Git sometimes does things like magic. But the magic it shows how it stores it information internally. Let’s discuss the fundamentals.

Okay, we have created an empty directory named git-internal and we initialised git in that directory. We can see the basic file structure inside .git folder which is the folder used by git to store all information.
Lets create a file main.go and modify so that after modification, the directory and content looks like this:

There is no change in .git directory so far. Let’s use git hash-object command to find out the SHA1 hash of main.go file using git hash-object main.go. git hash-object gives you the object id of a file, in our case main.go

Now, let’s add main.go file to git using git add main.go and see what has been changed in .git directory

If you notice then, you can see the SHA1 hash from the git hash-object main.go is used to denote a directory and a file. More specifically , first two character is used as a upper level directory, and the rest of 38 character is used to denote a file inside that directory. It’s a zlib compressed file which contains a header and the content of the file.
I suppose, this doesn’t answer clearly what is happening behind the curtain. So let’s dive into details.
In git, there is three kinds of objects
- blobs
- trees
- commits
we have our main.go file. The process of generating the corresponding filename(in our case 99/fd8050e485c174e01c4e074041e41ae09bae59) and content of the file is as follows:
- Git first constructs a header which starts by identifying the type of object — in this case, a blob. To that first part of the header, Git adds a space followed by the size in bytes of the content, and adding a final null byte
- Git concatenates the header and the original content and then calculates the SHA-1 checksum of that new content. This SHA1 has is the same as
git hash-object main.gooutput

Now that we know, how the SHA1 hash and the file name corresponding to that file is created. The content of that file is the zlib compressed version of value stored in store variable. To verify that, I have written a piece of code, that opens the file, decompresses using zlib format, and displays into terminal

Now this point, it should be clear that only the content of the file matters, the name or file permission doesn’t matter to this point at all. The file is just a zlib compressed data(header + file content). To prove this point, see the following picture:

Okay, now let’s create a commit and see what’s the status ? So, we run git commit -m "first commit" and let’s see what is changed in the object directory

Now, we see two new file created on this directory. So, we know 99/fd8050e485c174e01c4e074041e41ae09bae59 is correspond to the file main.go then what are the other files. To find out what is the type of object we can use git cat-file command. (Provide content or type and size information for repository objects)

So, we can see the other two types of objects in git. The tree type objects, basically holds the information
- File permission
- type of objects is has inside(blob/tree)
- hash of the objects
- name of the blob/tree(this is where, git knows about the existance of a file)
To generate the hash of the tree(b52e25f217248e21dec163465bd111bb6f723f0e)

We can see the format of the file, and how we generate these values.
For commit objects, we can see the same picture. Lets run this same thing for commit object file

Here we can see, the commit file 36/29dca9fc3a11108fcd229c8ed082ffa8761192 contains a header commit 197 and then information about tree, author, commiter, timestamp and commit message in zlib format.
The process to generate 40 byte hash and generate file content is exactly same, just the header and what information is included is different. store = \0 Hash = SHA1(store) file_name = Hash[0:2]/Hash[2:] file_content = zlib_compressed(store)


 and
and  then
then 
 denotes the number of integers <=n which is relatively prime to n. Two numbers a and b are called relatively prime, if gcd(a,b) = 1. here gcd denotes greatest common divisor.
denotes the number of integers <=n which is relatively prime to n. Two numbers a and b are called relatively prime, if gcd(a,b) = 1. here gcd denotes greatest common divisor.

 are
are  and the only way for
and the only way for 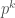 are
are  and there are
and there are  of them. Therefore, the other
of them. Therefore, the other  numbers are all relatively prime to
numbers are all relatively prime to 



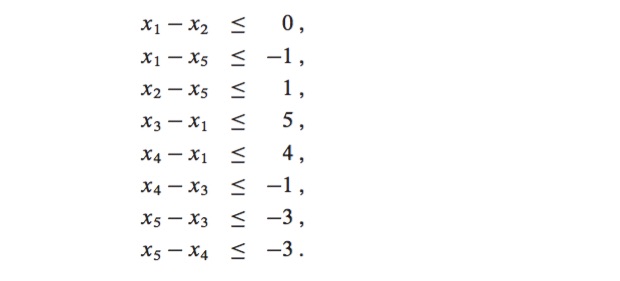
 such that we have operated Halum (v,
such that we have operated Halum (v,

